

With the first pick of the 2020 NBA Draft, the Golden State Warriors select…
Everyone is on the edge of their seats, waiting for which new NBA player will join the big three of Steph Curry, Klay Thompson, and Draymond Green. Everyone is waiting for who will be the lucky player that gets to rejuvenate the most dominant team of the past 6 years. The draftees are listening nervously as they hope that their name is the one said. This is the moment that everyone has been waiting for. The first pick of the draft will be announced.
The NBA Draft is one of the most important events of the sports year. The feeling felt by players, fans, and teams alike as a new draftee fulfills his NBA dream as they make their way up the stage is the thing that make the NBA Draft one of the most exciting times on the NBA calendar. Every year in the NBA Draft, a new class of talented players and stars enter the NBA. It is the one time of the year where bad teams are at the forefront of the NBA, searching for the face of their franchise for years to come. It is the day that the hard work of all the scouts and incoming players pay off. One of the most fascinating aspects of the NBA Draft is its unpredictability, as players drafted high don’t always become great players and some players drafted later develop into key players or superstars. But if there is a way to quantify the NBA Draft, then teams will have a significant advantage by knowing who to target and who to avoid. I tried to apply stats to the NBA Draft in order to predict how the draftees’ careers would project, using several different models. Then, I applied these models to this year in order to predict which players will become contributing players or all stars and which players will not live up to expectations.
MODELS
In order to try to predict the NBA Draft, I wanted to use more than one statistical model. Since players can develop into superstars, role players, or anything between, I made three different methods to quantify the players. The first thing I did was collect data on the first round draft picks from 2010 to 2017 and group them by position (guard, forward, and center). Then, I collected their college or international stats as inputs. The inputs varied across the different positions. They include age at draft, height, points per 36 minutes, true shooting percentage, free throw rate, and projected NBA 3 point percentage, among others. Then, after collecting the stats, I gave them three different metrics summarizing their contribution in the NBA at their prime. The first metric was a rating from 65 to 99 which summarizes the consensus quality of the player. These ratings are similar to ratings from the video game NBA 2K as superstars rated in the high 90s while average players were around 80 and bench players were in the 70s. The next metric was a binomial result of whether the player is worthy of playing quality minutes for a contending team, where a 1 denotes a contributing player while a 0 denotes a non-contributing player. The final metric was another binomial result showing whether or not the player is all star caliber, meaning they have either made an all star game or has a good chance of making one in the future.
Using these stats, I applied three statistical concepts to try to predict the results. The first was a multiple linear regression which used the inputs as the explanatory variables and the rating as the response variable. The next two were logistic regressions, which gave probabilities of the player becoming a contributor and an all star, respectively. The last step was to determine the accuracy of the three models. I found that accuracy of the rating regression was shaky as the r-squared was a low value of about 0.27. However, the accuracy of the logistic regressions were promising. The contributor logistic regression was accurate about 66% of the time if the probability was greater than 0.7, and it was accurate 79% of the time if the probability was less than 0.3. The all star regression was also promising, with 97% accuracy when the probability was below 0.125 and 46% accuracy when the probability was above 0.3. These accuracy rates show that the contributor and all star regressions were both very good at determining players that would not become good players, but only somewhat predictive of determining players who would become good players. Some of the notable successes of the all star regression were predicting that Giannis Antetokounmpo, Paul George, and Joel Embiid would become all stars. However, the model also had some misses as it predicted that Nerlens Noel and Al-Farouq Aminu would become all stars when they did not. The next step was to apply these models to the 2020 NBA Draft.
PREDICTIONS and CONCLUSIONS
I applied the three models to 38 different prospects from the 2020 NBA Draft. I chose prospects based on using five different mock drafts. Only possible first rounders were included. I created a human draft board by taking the average draft position of the prospects across the five mock drafts. The draft board is shown below. Then, I used the players’ stats as the inputs for the three models that I used. Keep in mind that for the ratings column, the r-squared was low meaning that most of the results will be near the average, which was about 77. Another facet of the statistics that may be confusing is that the probability of becoming an all star is greater than the probability of becoming a contributor for some players. This is because the sample did not include all possible players and stats, so some abnormalities are present. However, these players can be viewed as high risk players as the chance of being a role player but not an all star is low for them.
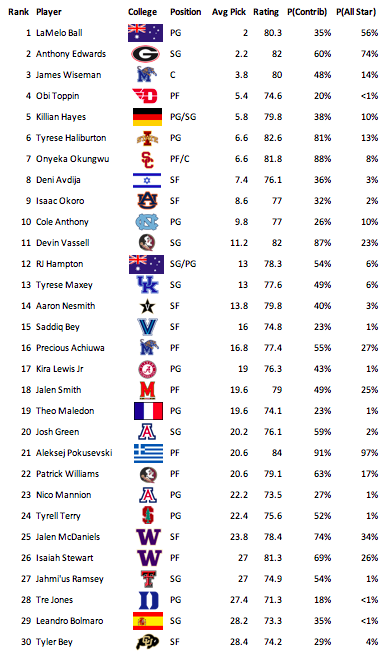
To create a draft board using the generated statistics, I averaged the ranks of each prospect in each regression. Since this draft board generated significantly different results than most draft rankings, I averaged the ranking of the human draft boards with the ranking of the statistical draft board to create one final modified draft board incorporating human scouting and statistical analysis. I wanted to include the human aspect since the models that I used only had nine inputs, meaning they could miss some aspects of a player which makes them special. Additionally, there are some intangibles that stats cannot account for, such as athleticism and work ethic, that are accounted for by human draft boards. The final modified draft board is shown below.
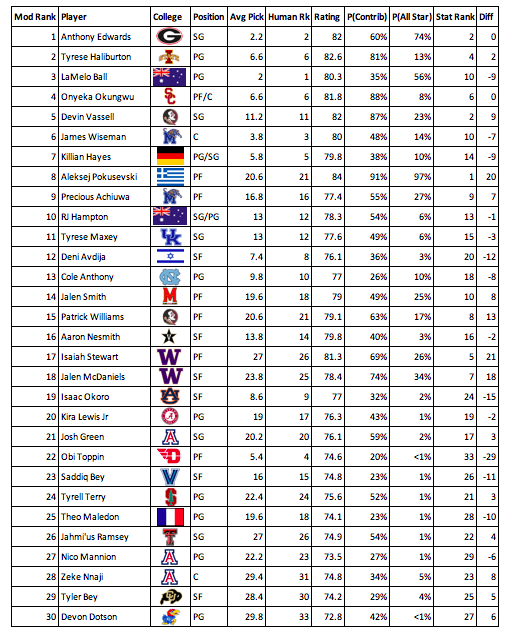
There are many conclusions that can be made from the modified draft board and the generated statistics. The first is that the player who is most likely to become a contributor and an all star according to the models is Aleksej Pokusevski, a tall power forward from Greece. The probability of becoming an all star is astronomically high at 97%. None of the observations while collecting the data had a chance of becoming an all star greater than 78%. Pokusevski is a young, versatile big who can handle the ball well and generate points from scoring or distributing, while also giving defensive contribution with his rim protection. Another interesting conclusion is that Onyeka Okungwu, a center from USC, seems to be a very safe prospect with a high chance of becoming a contributor, but a low chance of becoming an all star. Okungwu is a rim protecting center who doesn’t create many points with offense but prevents points with his defense. He seems to be an ideal pick for a team looking for quality starters but not a franchise player, such as the Hawks or the Warriors, but not a player worthy of the top pick as his chance of being an all star is very low. One player who was surprisingly low among all the metrics was Obi Toppin, the national player of the year for college basketball. However, Toppin is relatively old and does not have the defensive skills expected of a tall player. He was in the bottom five of probability of becoming a contributor, and his chance of becoming an all star is less than 1%. Keep in mind that this model was 97% accurate when predicting a chance of being an all star less than 12.5%, meaning that Toppin has a very low ceiling.

The most interesting topic of debate for this years NBA Draft is who will go first overall. In most years, there is a consensus player who is thought to be the first overall pick, such as Zion Williamson last year. However, this year is different with several possibilities for the number one pick, such as LaMelo Ball, Anthony Edwards, Killian Hayes, or James Wiseman. Using the three models, Anthony Edwards seems to be the best choice for the number one draft pick. Edwards ranked the highest among the possible first overall picks in probability of becoming an all star and projected rating. He is a shooting guard from Georgia who has the ability to create on offense, but lacks defensive ability and is an average distributor. Edwards is first on the modified draft board and has the second highest chance of becoming an all star in the whole draft class, behind only Pokusevski. Moreover, he can be viewed as a risky player as his chance of becoming an all star is greater than his chance of becoming a contributor.

I think that one of the most important part of the NBA Draft process is figuring out which players can be steals and which players should be avoided. By taking the difference between the human rank and the statistical rank, the undervalued and overvalued players can be found. The most undervalued player is Aleksej Pokusevski, a player that my metrics love and could be the steal of the draft. Other undervalued players include Isaiah Stewart, Jaden McDaniels, Patrick Williams, and Jalen Smith. The most overvalued players are Obi Toppin, Isaac Okoro, and Deni Avdija, each of whom are possible top ten picks but should probably be avoided until later in the draft. I have constructed a mock draft using the combined human rankings and statistical rankings, in addition to my own opinions about each player and where they would fit the best. I also included a lottery simulation to make the mock draft more fun for me to make, so the draft order will likely not be the same in the real draft.
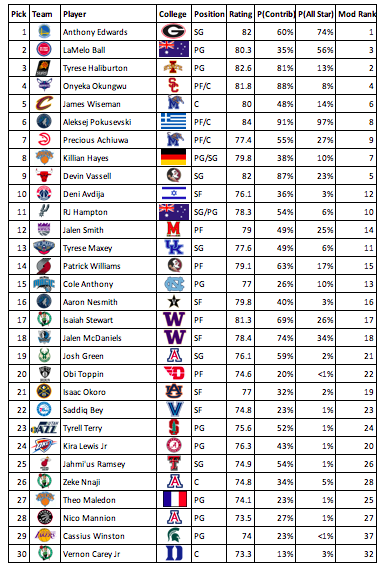
The NBA Draft is a huge event that shapes the careers of the young draftees as well as the outlook of general mangers across the NBA. The NBA can change with one singular pick, such as when Greg Oden was taken before Kevin Durant or when Kobe Bryant was not taken in the top 10. The teams with the most success are often the best at drafting players, such as the Celtics when they traded down and drafted Jayson Tatum instead of staying put and taking Markelle Fultz. Drafting is one of the most important parts of professional basketball teams, especially small market teams, as the only other ways to acquire talented players are via free agency (which usually only works out for big market teams like the Lakers) or trades (which require some good young players to get anyone of exceptional quality). Stats can be used to help teams gain insight on which players to take a closer look at and which players to avoid. The draft is an annual spectacle that changes the NBA landscape greatly.
DRAWBACKS
While proving helpful for locating steals and busts, there are a few issues with the models that I constructed for predicting the draft. One is that I divided the sample players into three different positional groups, so the regression equations and inputs are different for each positional group. Therefore, using one equation for the probability of becoming an all star will produce a different outcome than using the equation of the probability of an all star for a different positional group. In order to minimize mistakes, I tried to assign positions to players based on views by multiple websites and my own judgement. However, some players can be justified being in two different positional groups. Another drawback is that I only used nine inputs for each positional group when constructing the models. I was limited to the amount of stats that I could use because I wanted to include international players, but the stats for international players are not as readily available as those for collegiate players. Additionally, I did not want to use too much time recording so many different inputs that do not make logical sense to use to predict a player’s success for a certain position. For example, I did not use assists as an input for the centers since the role of a center is rebounding and rim protection most of the time, not distributing. The last drawback is that sometimes the results do not make sense, such as when the probability of becoming an all star is greater than the probability of becoming a contributor. This is probably a result of the sample size, which I limited to the draftees from 2010 to 2017 as these are the players that I have the most knowledge about, and advanced stats for college or international players before 2010 are difficult to acquire.
